Speech Assistance for Persons With Speech Impediments Using Artificial Neural Networks
Ramy Mounir, Redwan Alqasemi, Rajiv Dubey
Abstract
This work highlights the different techniques used in deep learning to achieve ASR and how it can be modified to recognize and dictate speech from individuals with speech impediments.
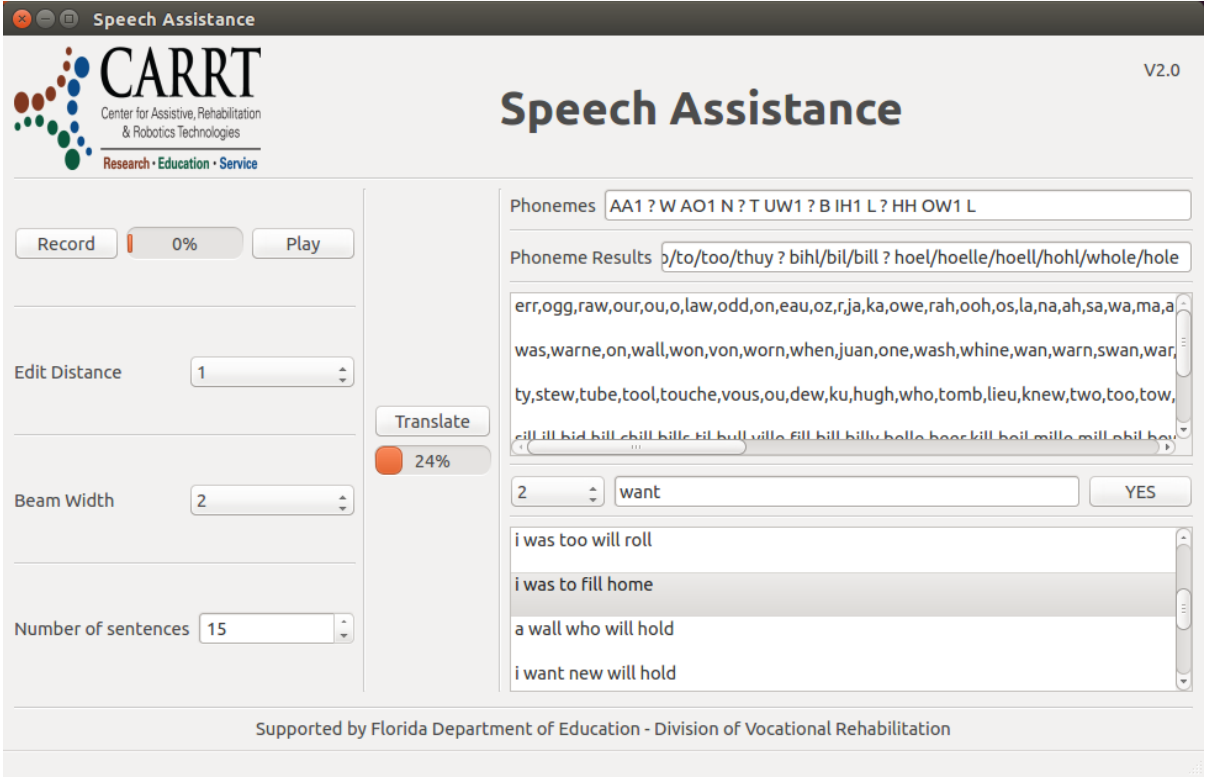
Approach
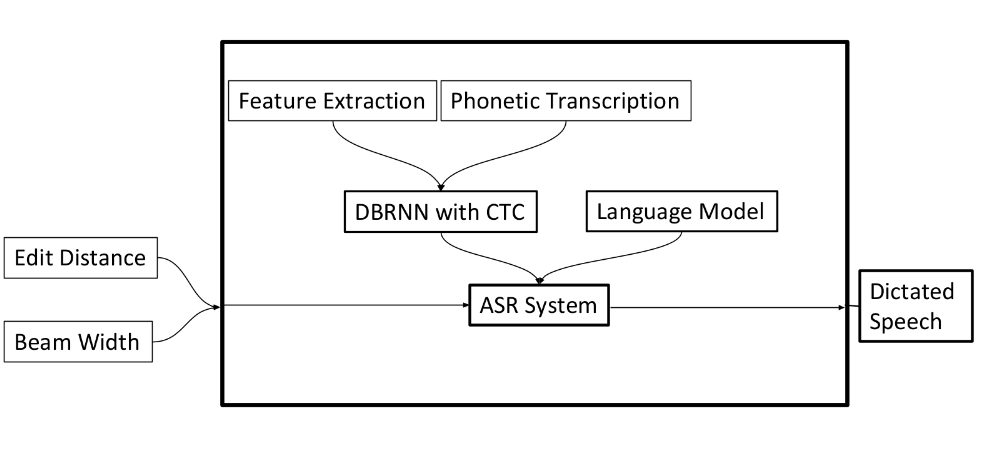
Deep Bidirectional LSTMs
We use deep bidirectional LSTM to train the language model. Connectionist Temporal Classification layer is added to the end of the network to allow the network to predict labels at any point in the sequence, it does not require the data to be segmented or aligned beforehand. The bidirectional LSTM allows the language model to predict given input from the past and the future, which makes the representations more robust when both directions are combined. The deep (multi-layer) architecture allows the model to build more abstract and high-level representations of the input.
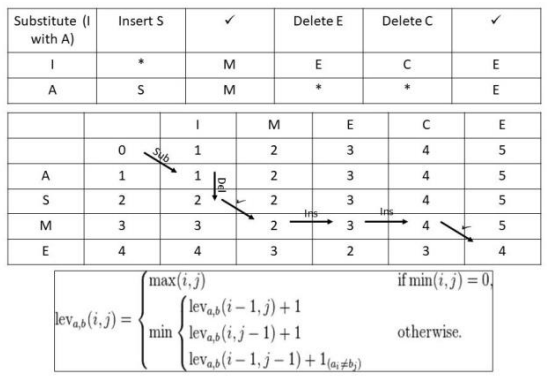
Levenshtein Edit Distance
Levenshtein edit distance is the function that calculates the minimum edit distance from one list of phonemes to another. In other words, it calculates the number of inserts, deletes and substitutions required to output the minimum combined edit distance value. Figure below shows an example of calculating the edit distance of “IMECE” to “ASME” using dynamic programming.
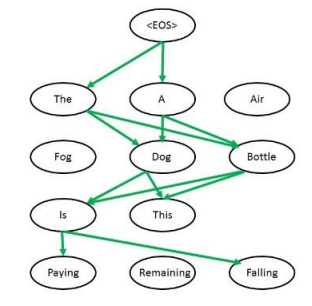
Beam Search Decoding
Depending on the beam width K, the method chooses the highest K paths at each step and continues in each path individually. The result is several sentences (depending on the K value and number of steps). The sentences can be compared using the [EOS] token, by checking the probability of the [EOS] token to occur after each sentence. The sentence with the highest probability is the outcome of this method.
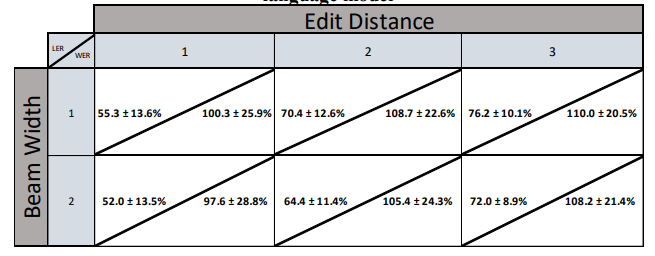
Label/Word Error Rates
Table below shows the LER and WER, including standard deviations for ASR + PTB dataset. As shown in results, the increase in beam width has resulted in a decrease in the error (as expected). The increase in edit distance resulted in an increase in the error because the test audio files do not include audio with speech impediment.
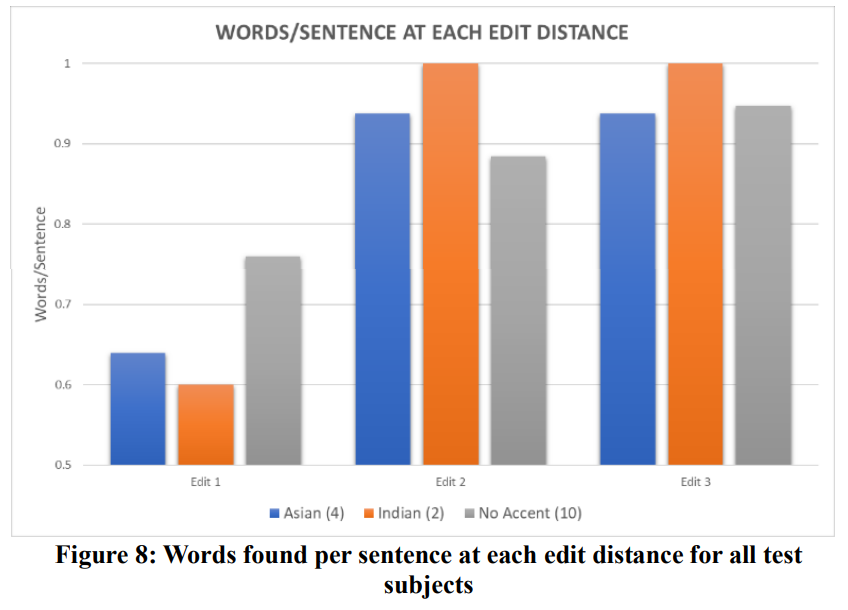
Words/Sentence Vs. Edit Distance
Figure below shows how many words per sentence were found by the test subjects in the potential words at each edit distance. Test subjects having no accents were able to find significantly more words, at an edit distance of one, than subjects with accents. As we increase the edit distance, the words/sentence found increase for all the data points. This concludes that it is recommended to increase the edit distance for data with speech impediment to acquire better results (given a good language model). The number shown after each accent in the legend represents the data points count.
Acknowledgements
The work was supported by the Florida Department of Education - Division of Vocational Rehabilitation.
Citation
@misc{speechassistance,
title = {Speech Assistance for Persons With Speech Impediments Using Artificial Neural Networks},
author = {Ramy Mounir and Redwan Alqasemi and Rajiv Dubey},
booktitle = {International Mechanical Engineering Congress & Exposition},
year = {2017},
note = {IMECE},
award = {Oral}
}