
About Me
I received my Ph.D. in Computer Science and a Master's degree in Mechanical Engineering from the University of South Florida, specializing in online compositional learning, biologically inspired perception, and robotics. My research focuses on the learning principles of the brain and the mechanisms underlying perception, reasoning, and prediction.
I am currently a researcher on the Thousand Brains Project , where we build neuroscience-inspired intelligent machines by reverse engineering the neocortex.
Latest News
Recent updates and announcements
- 12/2024 Started fulltime researcher position on the Thousand Brains Project!!
- 08/2024 Our paper "Predictive Attractor Models" has been accepted at NeurIPS'24!!
- 04/2024 I was awarded the Dissertation Completion Fellowship at USF!
- 12/2023 I will be interning at Numenta this Summer!!
- 08/2023 Our paper "STREAMER: Streaming Representation Learning and Event Segmentation..." has been accepted at NeurIPS'23!!
- 06/2022 Our paper "Bayesian Tracking of Video Graphs..." has been accepted at ECCV'22(Oral)!
Book Chapters
Contributions to academic publications

Advanced Methods and Deep Learning in Computer Vision (Chapter 12)
Ramy Mounir, Sathyanarayanan N. Aakur , Sudeep Sarkar
Elsevier, ISBN: 9780128221099
We discuss three perceptual prediction models from EST in three progressive versions...
Publications
Peer-reviewed research contributions
-
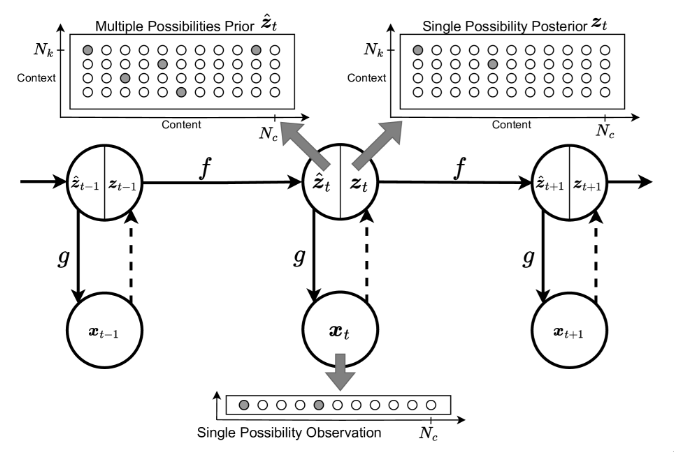 2024 NeurIPS
2024 NeurIPSPredictive Attractor Models
Ramy Mounir, Sudeep Sarkar
Advances in Neural Information Processing Systems
We propose PAM, a novel sequence memory architecture with desirable generative properties. PAM is a streaming model that learns a sequence in an online, continuous manner by observing each input only once. Additionally, we find that PAM avoids catastrophic forgetting by uniquely representing past context through lateral inhibition in cortical minicolumns, which prevents new memories from overwriting previously learned knowledge. PAM generates future predictions by sampling from a union set of predicted possibilities; this generative ability is realized through an attractor model trained alongside the predictor. We show that PAM is trained with local computations through Hebbian plasticity rules in a biologically plausible framework. Other desirable traits (e.g., noise tolerance, CPU-based learning, capacity scaling) are discussed throughout the paper.
-
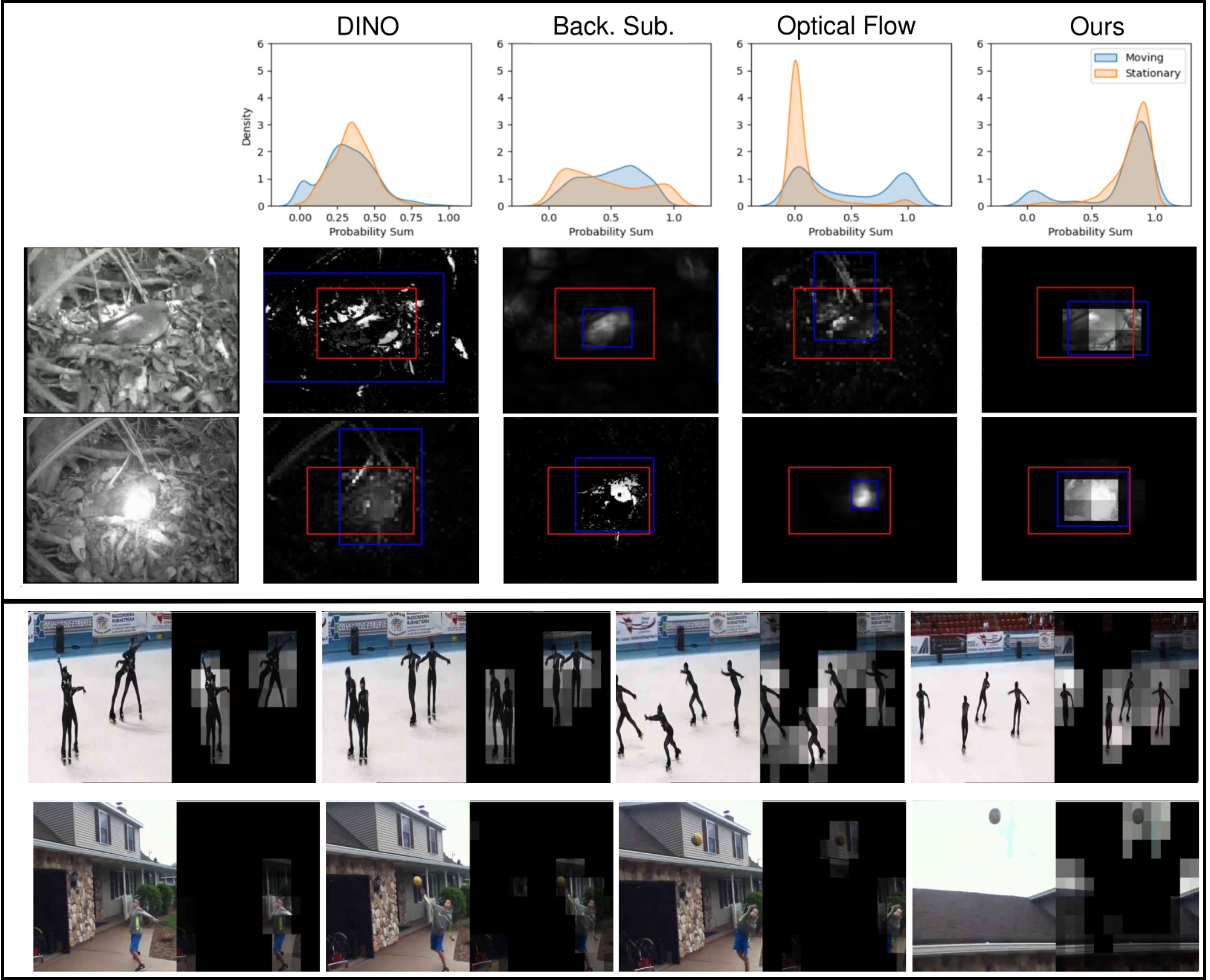 2023 IJCV
2023 IJCVTowards Automated Ethogramming: Cognitively-Inspired Event Segmentation for Wildlife Monitoring
Ramy Mounir, Ahmed Shahabaz, Roman Gula, Jorn Theuerkauf, Sudeep Sarkar
International Journal of Computer Vision
Advances in visual perceptual tasks have been mainly driven by the amount, and types, of annotations of large scale datasets. Inspired by cognitive theories, we present a self-supervised perceptual prediction framework to tackle the problem of temporal event segmentation. Our approach is trained in an online manner on streaming input and requires only a single pass through the video, with no separate training set. Given the lack of long and realistic (includes real-world challenges) datasets, we introduce a new wildlife video dataset – nest monitoring of the Kagu (a flightless bird from New Caledonia) – to benchmark our approach. Our dataset features a video from 10 days (over 23 million frames) of continuous monitoring of the Kagu in its natural habitat. We annotate every frame with bounding boxes and event labels. Additionally, each frame is annotated with time-of-day and illumination conditions.
-
 2023 IJCAI
2023 IJCAILong-term Monitoring of Bird Flocks in the Wild
Kshitiz, Sonu Shreshtha, Ramy Mounir, Mayank Vatsa, Richa Singh, Saket Anand, Sudeep Sarkar, Severam Mali Parihar
International Joint Conference on Artificial Intelligence
The work highlights the importance of monitoring wildlife for conservation and conflict management. It highlights the success of AI-based camera traps in planning conservation efforts. This project, part of the NSF-TIH Indo-US partnership, aims to analyze longer bird videos, addressing challenges in video analysis at feeding and nesting sites. The goal is to create datasets and tools for automated video analysis to understand bird behavior. A major achievement is a dataset of high-quality images of Demoiselle cranes, revealing issues with current methods in tasks like segmentation and detection. The ongoing project aims to expand the dataset and develop better video analytics for wildlife monitoring.
-
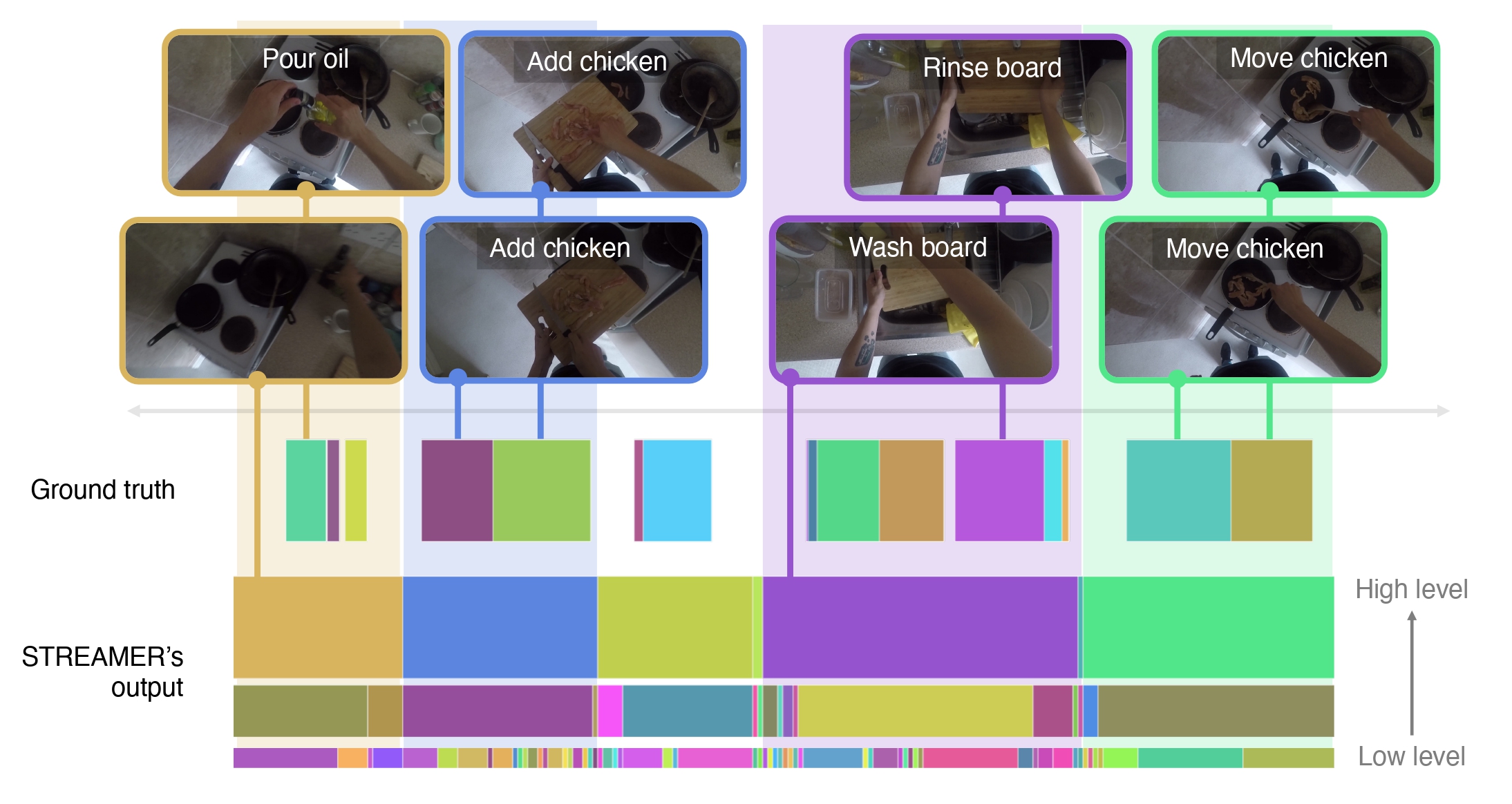 2023 NeurIPS
2023 NeurIPSSTREAMER: Streaming Representation Learning and Event Segmentation in a Hierarchical Manner
Ramy Mounir, Sujal Vijayaraghavan, Sudeep Sarkar
Advances in Neural Information Processing Systems
We present a novel self-supervised approach for hierarchical representation learning and segmentation of perceptual inputs in a streaming fashion. Our research addresses how to semantically group streaming inputs into chunks at various levels of a hierarchy while simultaneously learning, for each chunk, robust global representations throughout the domain. To achieve this, we propose STREAMER, an architecture that is trained layer-by-layer, adapting to the complexity of the input domain. Notably, our model is fully self-supervised and trained in a streaming manner, enabling a single pass on the training data. We evaluate the performance of our model on the egocentric EPIC-KITCHENS dataset, specifically focusing on temporal event segmentation. Furthermore, we conduct event retrieval experiments using the learned representations to demonstrate the high quality of our video event representations.
-
 2022 ECCV Oral
2022 ECCV OralBayesian Tracking of Video Graphs Using Joint Kalman Smoothing and Registration
Aditi Bal, Ramy Mounir, Sathyanarayanan Aakur, Sudeep Sarkar, Anuj Srivastava
European Conference on Computer Vision
Graph-based representations are becoming increasingly popular for representing and analyzing video data, especially in object tracking and scene understanding applications. Accordingly, an essential tool in this approach is to generate statistical inferences for graphical time series associated with videos. This paper develops a Kalman-smoothing method for estimating graphs from noisy, cluttered, and incomplete data.
-
 2021 CVIP Oral
2021 CVIP OralSpatio-Temporal Event Segmentation for Wildlife Extended Videos
Ramy Mounir, Roman Gula, Jorn Theuerkauf, Sudeep Sarkar
International Conference on Computer Vision & Image Processing
We present a self-supervised perceptual prediction framework capable of temporal event segmentation by building stable representations of objects over time and demonstrate it on long videos, spanning several days. The self-learned attention maps effectively localize and track the event-related objects in each frame. The proposed approach does not require labels. It requires only a single pass through the video, with no separate training set.


Work Experience
Professional journey and career milestones
- 01 / 2025 - Present Fulltime Researcher at Thousand Brains Project
- Summer 2024 Research Intern at Numenta
- Summer 2023 Computer Vision Research Intern at Mitsubishi Electric Research Labs (MERL)
- 08 / 2016 - 05 / 2024 Graduate Research & Teaching Assistant at USF
- 12 / 2014 - 10 / 2016 R&D Engineer at EarthLinked Technologies, Inc.
Funding & Grants
Research support and recognition
-
USF - Grad Studies
Dissertation Completion Fellowship
$10,000.00 (1-Semester)
-
Reviewer Service
Contributing to the academic community
- 2024 CVPR, NeurIPS, ICLR, ECCV, ICML, WACV
- 2023 CVPR, TPAMI, ICML, NeurIPS, ICCV, WACV, IEEE RA-L
- 2022 CVPR, ECCV [Outstanding], NeurIPS, ICLR [Highlighted], WACV, IEEE RA-L, ACMMM
- 2021 CLVision@CVPR, ACMMM
Talks and Presentations
Sharing research with the community
- 2025 Behaviors and Reference Frames, Thousand Brains Project
- 2025 Looking Inside Monty's Brain, Thousand Brains Project
- 2025 tbp.plot, Widgets, and Pub-Sub Pattern, Thousand Brains Project
- 2023 Self-Supervised Event Segmentation for Wildlife Extended Monitoring, Computer Vision grad course
- 2023 Streaming Representation Learning and Event Segmentation in a Hierarchical Manner, Numenta
- 2021 Self-Supervised Representation Learning, AI+X Seminar
- 2021 Self-Supervised Temporal Event Segmentation, Computer Vision grad course
Blog Articles
Technical tutorials and insights
Teaching Experience
Educational contributions and mentorship
- Fall'16 - Spring'17 Teacher Assistant, Capstone Design, USF
- Fall'18 - Spring'20 Teacher Assistant, Capstone Design, USF
- Fall'17 - Spring'18 Teacher Assistant, Mechanical Engineering Lab I, USF
- Summer'18 Teacher Assistant, Programming Concepts, USF
Let's Connect
Interested in collaboration or have questions about my research? Feel free to reach out!