STREAMER: Streaming Representation Learning and Event Segmentation in a Hierarchical Manner
Ramy Mounir, Sujal Vijayaraghavan, Sudeep Sarkar
Abstract
We present a novel self-supervised approach for hierarchical representation learning and segmentation of perceptual inputs in a streaming fashion. Our research addresses how to semantically group streaming inputs into chunks at various levels of a hierarchy while simultaneously learning, for each chunk, robust global representations throughout the domain. To achieve this, we propose STREAMER, an architecture that is trained layer-by-layer, adapting to the complexity of the input domain. Notably, our model is fully self-supervised and trained in a streaming manner, enabling a single pass on the training data. We evaluate the performance of our model on the egocentric EPIC-KITCHENS dataset, specifically focusing on temporal event segmentation. Furthermore, we conduct event retrieval experiments using the learned representations to demonstrate the high quality of our video event representations.
Approach
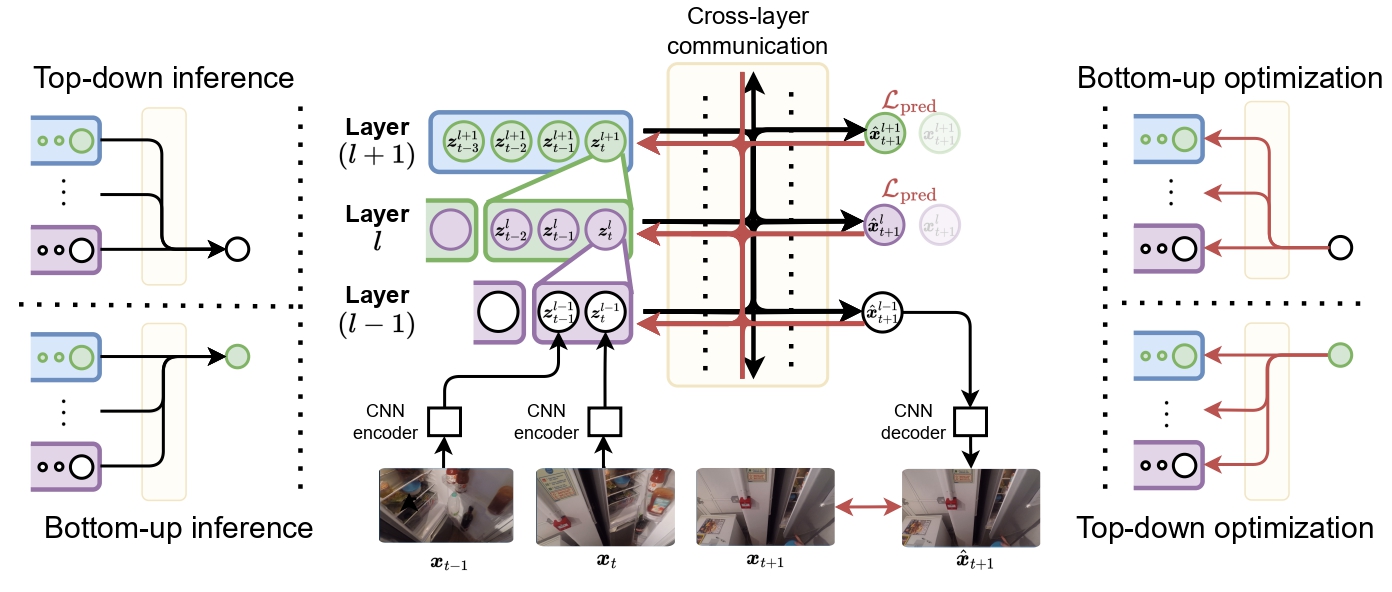
Overview of our full architecture. Given a stream of inputs at any layer, our model combines them and generates a bottleneck representation, which becomes the input to the level above it. The cross-layer communication could be broken down into top-down and bottom-up contextualized inference (left) and optimization (right).
Information Flow
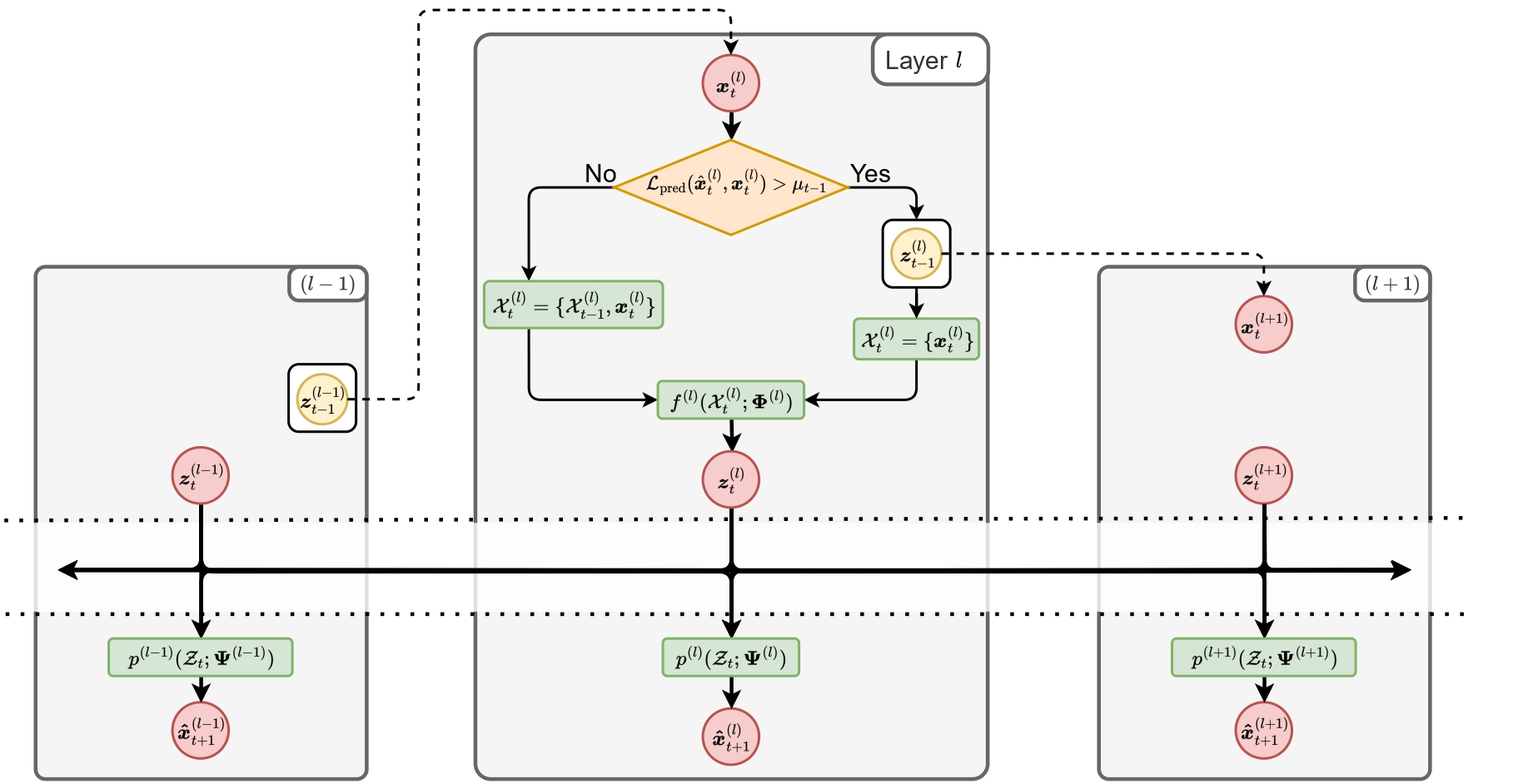
A diagram illustrating information flow across stacked identical layers. Each layer compares its prediction x̂ₜ with the input xₜ received from the layer below. If the prediction error L_pred is over a threshold μₜ₋₁, the current representation zₜ₋₁ becomes the input to the layer above, and the working set is reset with xₜ; otherwise, xₜ is appended to the working set Xₜ.
Video Presentation
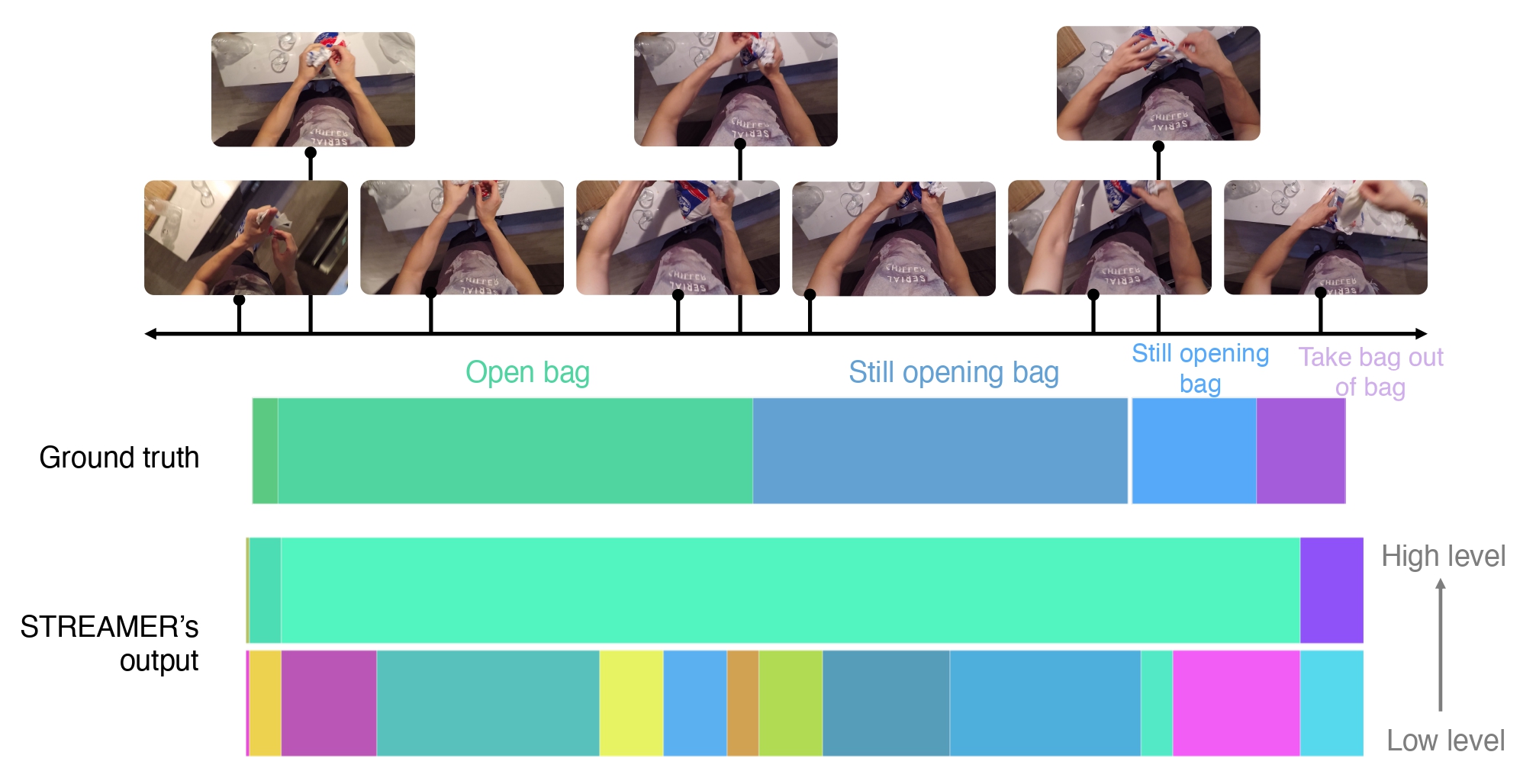
Examples & Results
Numenta Talk
Further Information
If you like this project, please check out other related works from our group:
- Mounir et al. - Towards Automated Ethogramming: Cognitively-Inspired Event Segmentation for Wildlife Monitoring (IJCV 2023)
- Mounir et al. - Spatio-Temporal Event Segmentation for Wildlife Extended Video (CVIP 2021)
- Mounir et al. - Self-Supervised Temporal Event Segmentation Inspired by Cognitive Theories (Book Chapter)
- Aakur et al. - A Perceptual Prediction Framework for Self Supervised Event Segmentation (CVPR 2019)
Acknowledgements
This research was supported by the US National Science Foundation Grants CNS 1513126 and IIS 1956050. The authors would like to thank Margrate Selwaness for her help with results visualizations.
Citation
@misc{streamer,
title = {STREAMER: Streaming Representation Learning and Event Segmentation in a Hierarchical Manner},
author = {Ramy Mounir and Sujal Vijayaraghavan and Sudeep Sarkar},
booktitle = {Advances in Neural Information Processing Systems},
year = {2023},
note = {NeurIPS}
}