Towards Automated Ethogramming: Cognitively-Inspired Event Segmentation for Wildlife Monitoring
Ramy Mounir, Ahmed Shahabaz, Roman Gula, Jorn Theuerkauf, Sudeep Sarkar
Abstract
Advances in visual perceptual tasks have been mainly driven by the amount, and types, of annotations of large scale datasets. Inspired by cognitive theories, we present a self-supervised perceptual prediction framework to tackle the problem of temporal event segmentation. Our approach is trained in an online manner on streaming input and requires only a single pass through the video, with no separate training set. Given the lack of long and realistic (includes real-world challenges) datasets, we introduce a new wildlife video dataset – nest monitoring of the Kagu (a flightless bird from New Caledonia) – to benchmark our approach. Our dataset features a video from 10 days (over 23 million frames) of continuous monitoring of the Kagu in its natural habitat. We annotate every frame with bounding boxes and event labels. Additionally, each frame is annotated with time-of-day and illumination conditions.
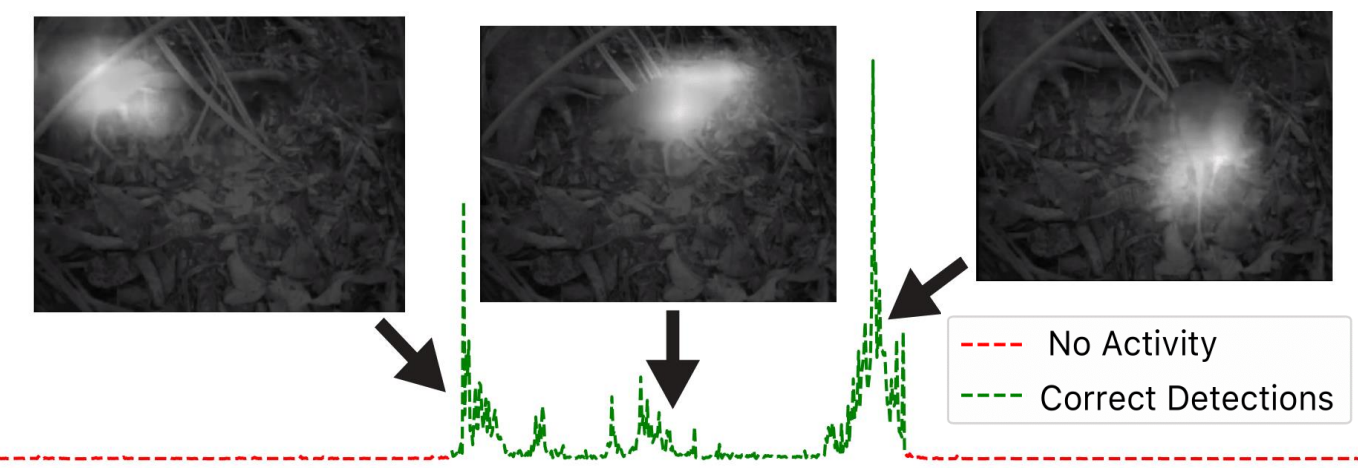
Approach
Approach
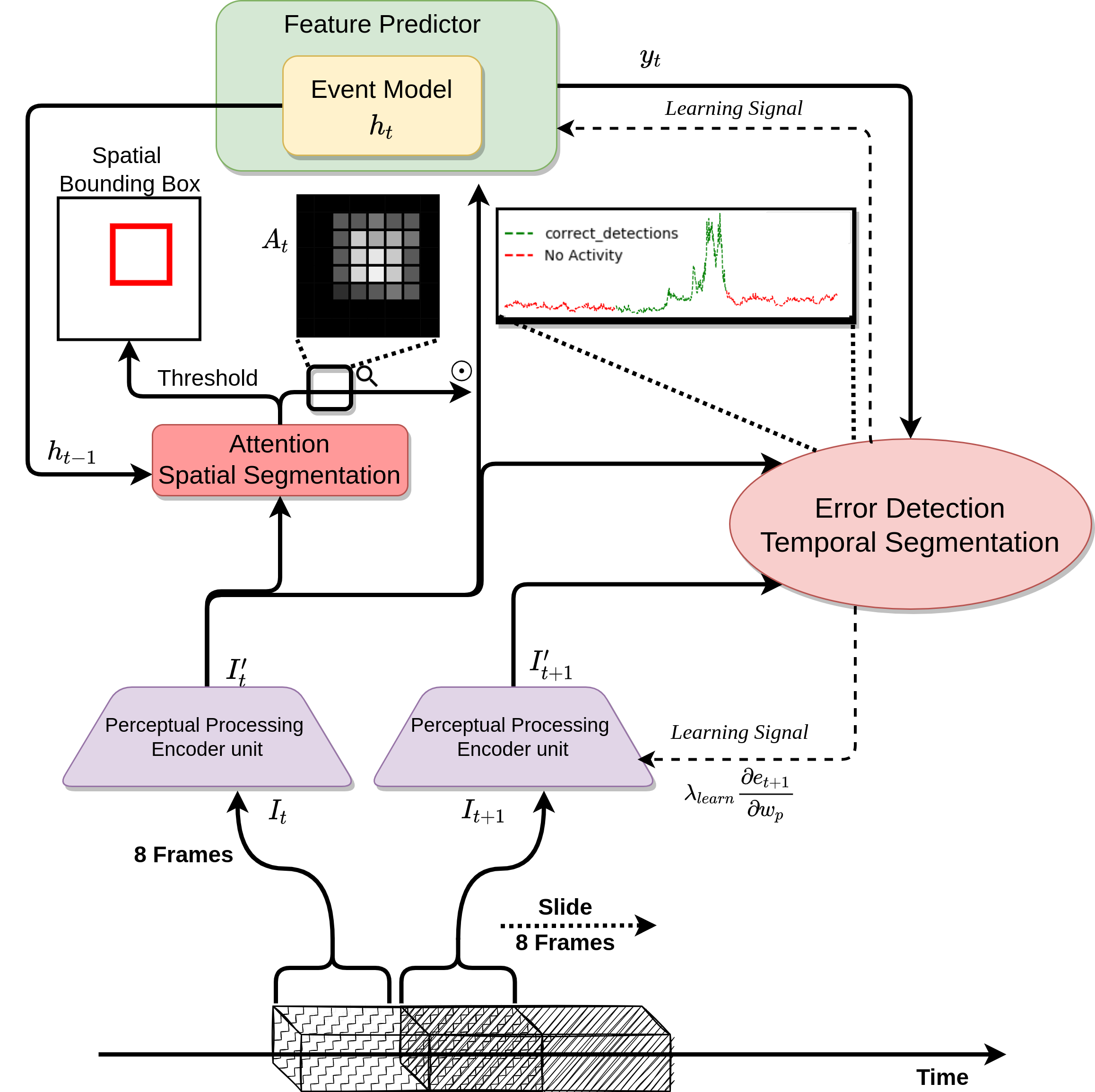
Overview of our full architecture. The perceptual processing unit encodes current frames and future frames into a grid feature representations. An attention operation is applied to the current features to spatially segment the event objects. The predictor combines the event model representation with the current features to predict the future features. Error in the prediction is used as a learning signal for the trainable weights. The spatio-temporal pooling layer receives as input spatial localization map and prediction error signal and outputs the detected events.
Poster

Further Information
If you like this project, please check out other related works from our group:
- Mounir et al. - STREAMER: Streaming Representation Learning and Event Segmentation in a Hierarchical Manner (NeurIPS 2023)
- Mounir et al. - Spatio-Temporal Event Segmentation for Wildlife Extended Video (CVIP 2021)
- Mounir et al. - Self-Supervised Temporal Event Segmentation Inspired by Cognitive Theories (Book Chapter)
- Aakur et al. - Learning Actor-centered Representations for Action Localization in Streaming Videos using Predictive Learning (ECCV 2022)
- Aakur et al. - A Perceptual Prediction Framework for Self Supervised Event Segmentation (CVPR 2019)
Acknowledgements
This research is supported by the US National Science Foundation grants CNS 1513126 and IIS 1956050. The bird video dataset used in this paper was made possible through funding from the Polish National Science Centre (grant NCN 2011/01/M/NZ8/03344 and 2018/29/B/NZ8/02312). Province Sud (New Caledonia) issued all permits required for data collection.
Citation
@misc{AutomatedEthogramming,
title = {Towards Automated Ethogramming: Cognitively-Inspired Event Segmentation for Wildlife Monitoring},
author = {Ramy Mounir and Ahmed Shahabaz and Roman Gula and Jorn Theuerkauf and Sudeep Sarkar},
booktitle = {International Journal of Computer Vision},
year = {2023},
note = {IJCV}
}