Spatio-Temporal Event Segmentation for Wildlife Extended Videos
Ramy Mounir, Roman Gula, Jorn Theuerkauf, Sudeep Sarkar
Abstract
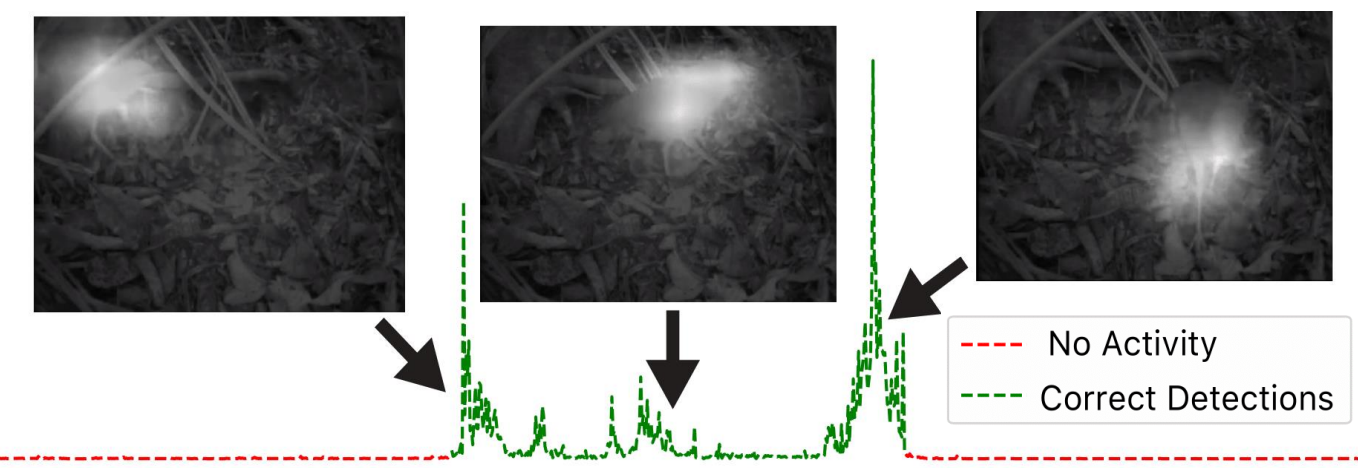
We present a self-supervised perceptual prediction framework capable of temporal event segmentation by building stable representations of objects over time and demonstrate it on long videos, spanning several days. The self-learned attention maps effectively localize and track the event-related objects in each frame. The proposed approach does not require labels. It requires only a single pass through the video, with no separate training set.
Approach
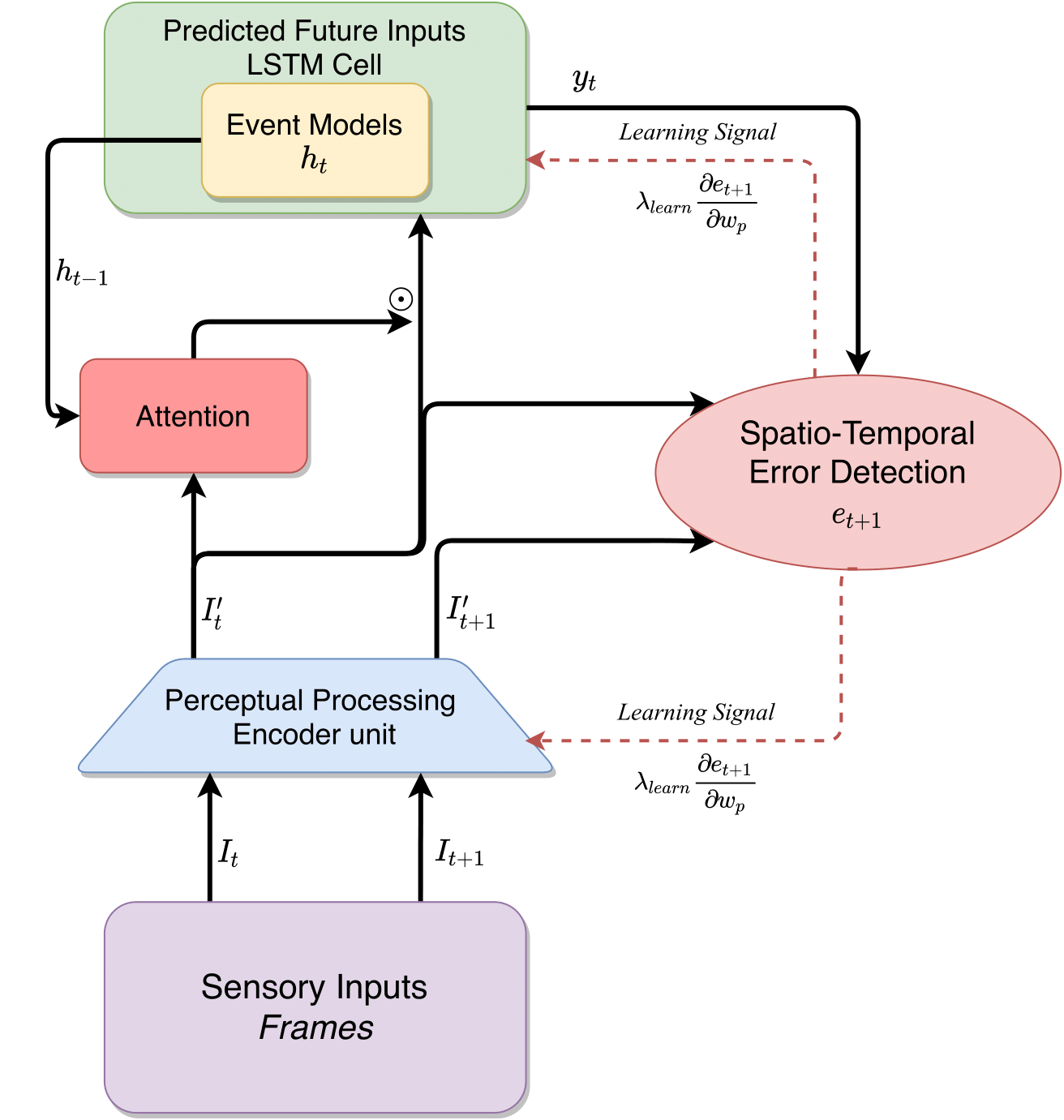
The architecture of the self-learning, perceptual prediction algorithm. Input frames from each time instant are encoded into high-level features using a deep-learning stack, followed by an attention overlay that is based on inputs from previous time instant, which is input to an LSTM. The training loss is composed based on the predicted and computed features from current and next frames.
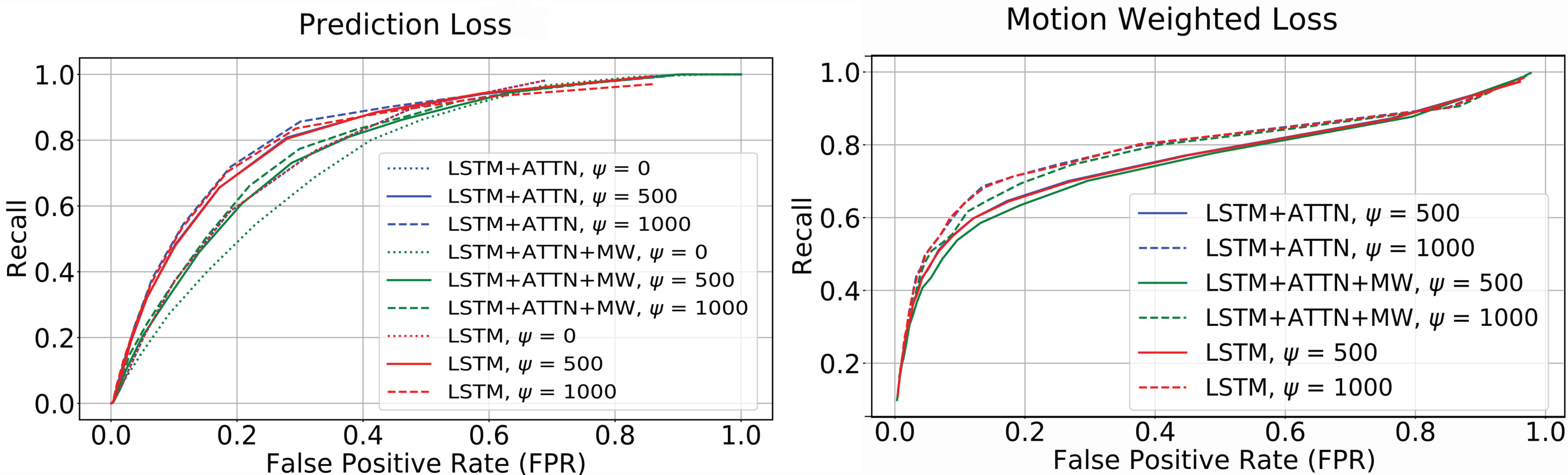
Frame-level event segmentation ROCs when activities are detected based on simple thresholding of the prediction and motion weighted loss signals. Plots are shown for different ablation studies.
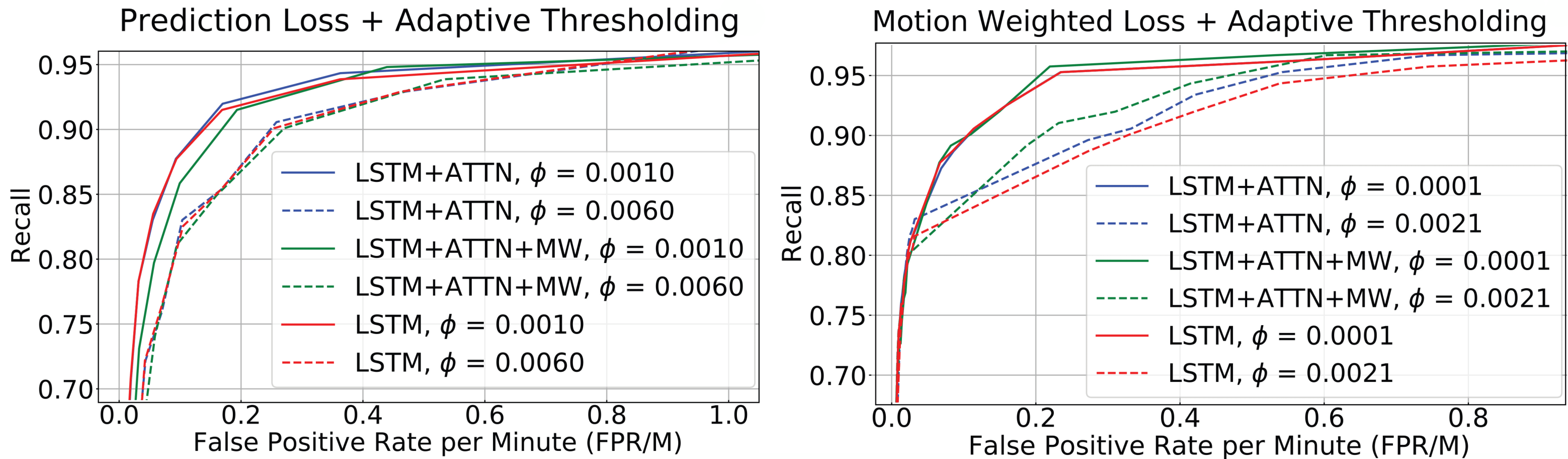
Activity-level event segmentation ROCs when activities are detected based on adaptive thresholding of the prediction and motion weighted loss signals. Plots are shown for different ablation studies.
Further Information
If you like this project, please check out other related works from our group:
- Mounir et al. - STREAMER: Streaming Representation Learning and Event Segmentation in a Hierarchical Manner (NeurIPS 2023)
- Mounir et al. - Towards Automated Ethogramming: Cognitively-Inspired Event Segmentation for Wildlife Monitoring (IJCV 2023)
- Mounir et al. - Self-Supervised Temporal Event Segmentation Inspired by Cognitive Theories (Book Chapter)
- Aakur et al. - A Perceptual Prediction Framework for Self Supervised Event Segmentation (CVPR 2019)
Acknowledgements
This dataset was made possible through funding from the Polish National Science Centre (grant NCN 2011/01/M/NZ8/03344 and 2018/29/B/NZ8/02312). Province Sud (New Caledonia) issued all permits - from 2002 to 2020 - required for data collection. This research was supported in part by the US National Science Foundation grant IIS 1956050.
Citation
@misc{EventSegmentation,
title = {Spatio-Temporal Event Segmentation for Wildlife Extended Videos},
author = {Ramy Mounir and Roman Gula and Jorn Theuerkauf and Sudeep Sarkar},
booktitle = {International Conference on Computer Vision & Image Processing},
year = {2021},
note = {CVIP},
award = {Oral}
}